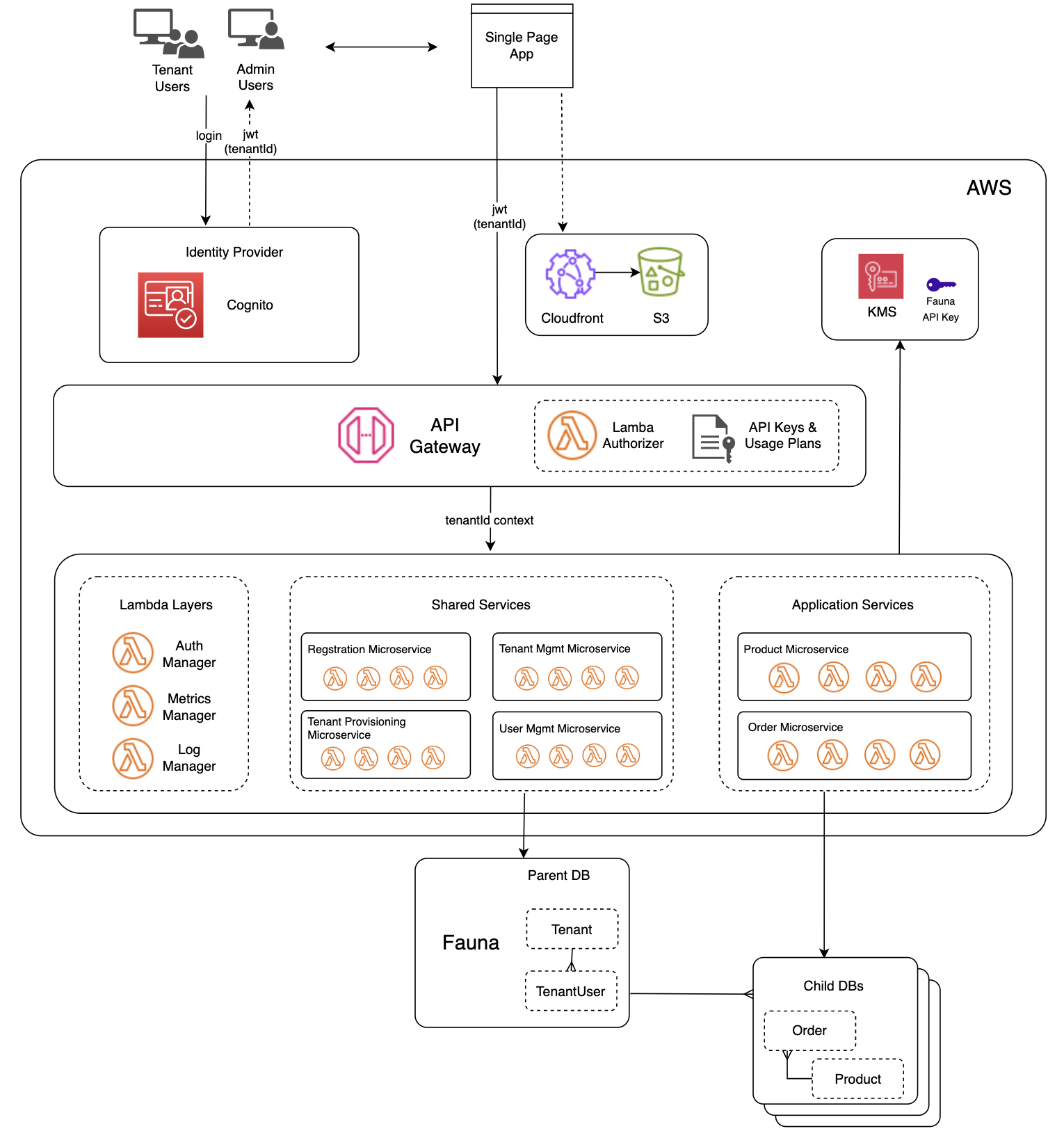
Reviewing the architecture
The diagram below depicts the overall architecture of the lab you just deployed.
What was updated?
SaaS Application Front-end
The web application combines the e-commerce app from Lab 1 with the SaaS Admin App from Lab 2 and also allows the user to toggle between them.
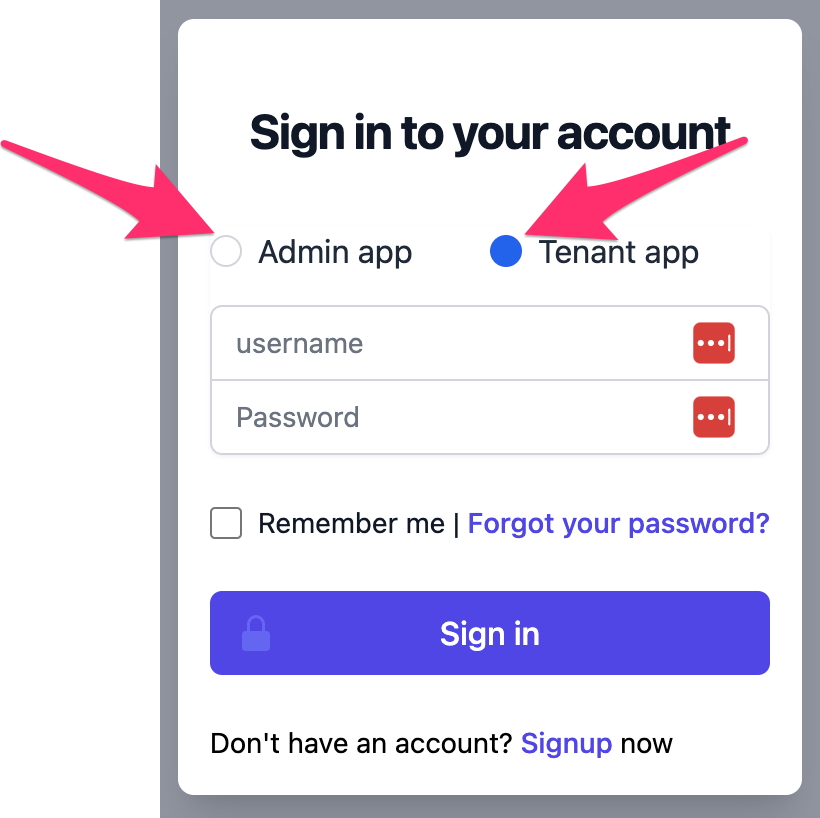
In Lab 1 we demonstrated a basic e-commerce web application which lacked any sort of authentication and multi-tenancy constructs. In this Lab, accessing the e-commerce application requires a login (select the Tenant app radio button).
Once authenticated, the Tenant app illustrates the interaction with the Product and Order microservices. More importantly, the user can only interact with their own tenant’s data.
Identity Provider
In a multi-tenant environment, the Identity Provider plays a key role in the architecture. When a user accesses the app, the first component they touch is the Identity Provider - the login process. Upon successful authentication, the Identity Provider provides the user context to the application.
After logging in to the Tenant app, Cognito sends a JWT token back to the UI. This JWT token contains the tenantId as a custom claim, which gets passed along with the JWT to the API Gateway.
The API Gateway then uses the Lambda Authorizer to validate the JWT token and extract the tenant context from it. The Lambda authorizer also works with the API Gateway to allow specific methods/routes based upon the user’s role. As an example, only system admins and tenant admins are able to create tenants.
This tenant context is also passed to the Lambda functions which then becomes the basis of enabling multi-tenant observability and tenant data segregation, as described below.
Hiding tenant details with Lambda Layers
SaaS solutions generally try to simplify the development of microservices by introducing libraries or modules that will abstract away many of the details associated with multi-tenancy. Logging, metrics, and data access may all require tenant context and we don’t want to require developers to have one-off code in each of their services to manage/access/apply this. We leverage a mechanism called Lambda Layers, that allow us to introduce common code that can be used to address these common multi-tenant needs.
This workshop uses Lambda Layers to centralize logging, metrics and tracing; We use the AWS Lambda Powertools library to write logs and metrics to Amazon CloudWatch and traces to AWS X-Ray.
Siloed approach to storing tenant data
Our schema design to achieve multi-tenancy leverages a unique Fauna feature that allows the association of databases as children of another. The Fauna API key we manage belongs to the “parent” database, but it is allowed scoped access to each of it’s “child” databases by simply appending the name of the child database to the key, as illustrated in the diagram below.
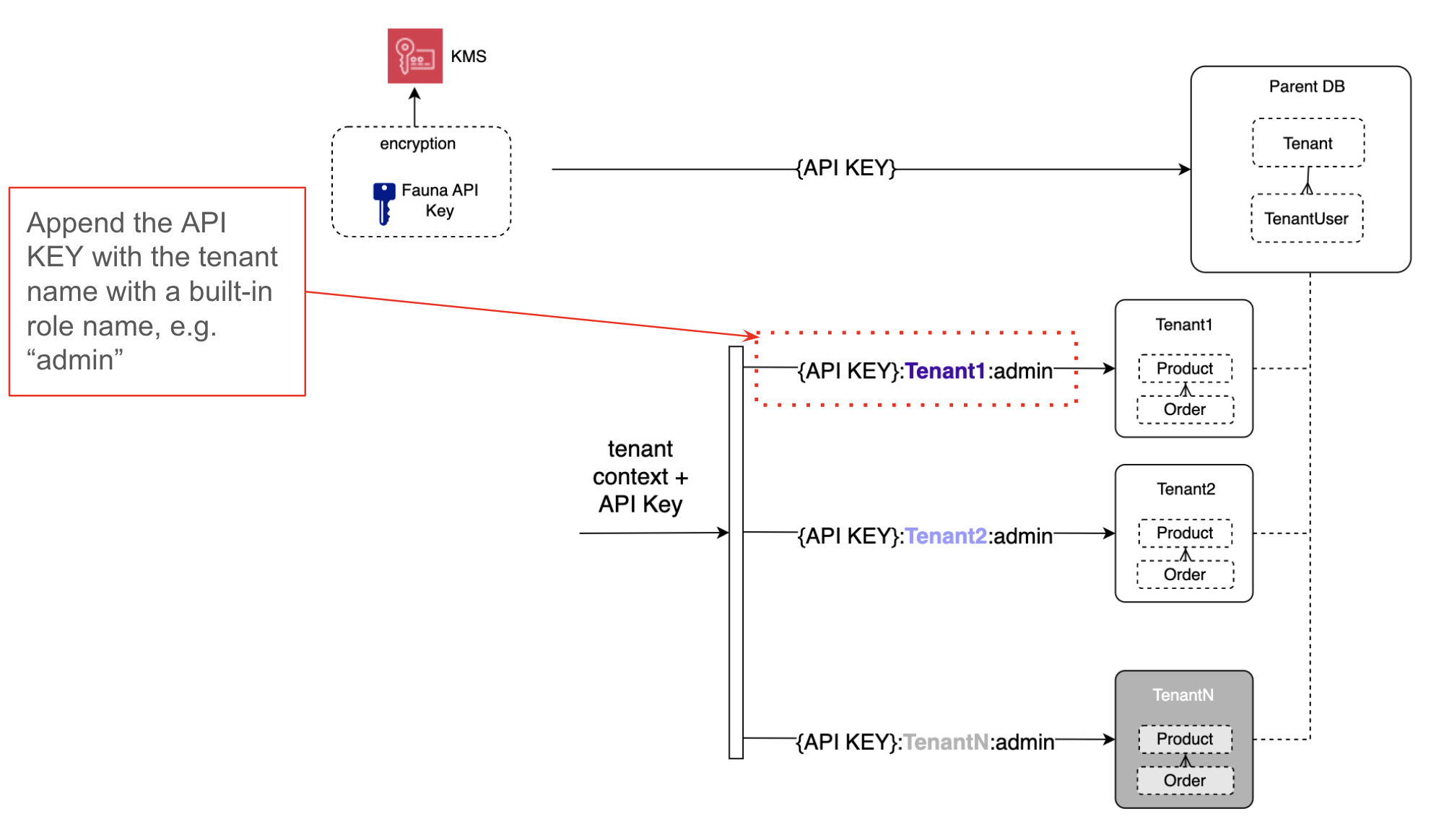
As previously mentioned, the tenant context is passed to the Lambda functions for logging, metrics and data access (i.e. accessing the database). Our code implements a utility that figures out the child database name based on the tenant context, and it appends the child database’s name to the Fauna API Key when accessing data. With this design, there is no need for partitioning of data within tables/collections due to tenancy, since all of the data in a database belongs to the same tenant that database is assigned to (otherwise known as the multitenancy siloed data approach).
Two benefits arise from this:
- All our functions and queries are written as if there is only a single tenant. And this greatly simplifies our code.
- The tenants’ data are fully segregated from one another.
In the next section, we explore the code to get a solid understanding of how this works.