Reviewing the code
Go back to your IDE and expand the Lab1 folder. You will see two sub-folders, client and server. The client sub-folder contains the project for the front end. The server sub-folder contains the code used to deploy the AWS infrastructure. Inside server, you will notice we have OrderService and ProductService folders, which represent our product and order microservices. Also notice the template.yaml file; As mentioned before, it file encodes the infrastructure that we deployed using the Serverless Application Model (SAM).
Continuing where we left off
Continuing from where we left off from in previous section, lets see how the query is written for the GET /orders API. Under the OrderService folder, open the order_service.py file:
Examine the get_orders function on line 179:
179def get_orders(event, context):
180 logger.info("Request received to get all orders")
181 try:
182 global db
183 if db is None:
184 db = Fauna.from_config(load_config())
185
186 response = db.query(
187 fql("""
188 order.all().map(o=>{
189 {
190 id: o.id,
191 orderName: o.orderName,
192 creationDate: o.creationDate,
193 status: o.status,
194 orderProducts: o.orderProducts.map(x=>{
195 price: x.price,
196 quantity: x.quantity,
197 productId: x.product.id,
198 productName: x.product.name,
199 productSku: x.product.sku,
200 productDescription: x.product.description
201 })
202 }
203 })
204 """)
205 )
206 logger.info("Request completed to get all orders")
207 orders = response.data.data
208 return utils.generate_response(orders)
209 except Exception as e:
210 return utils.generate_error_response(e)Copy the query highlighted and run it in the Fauna web shell. Here’s a sample screenshot:
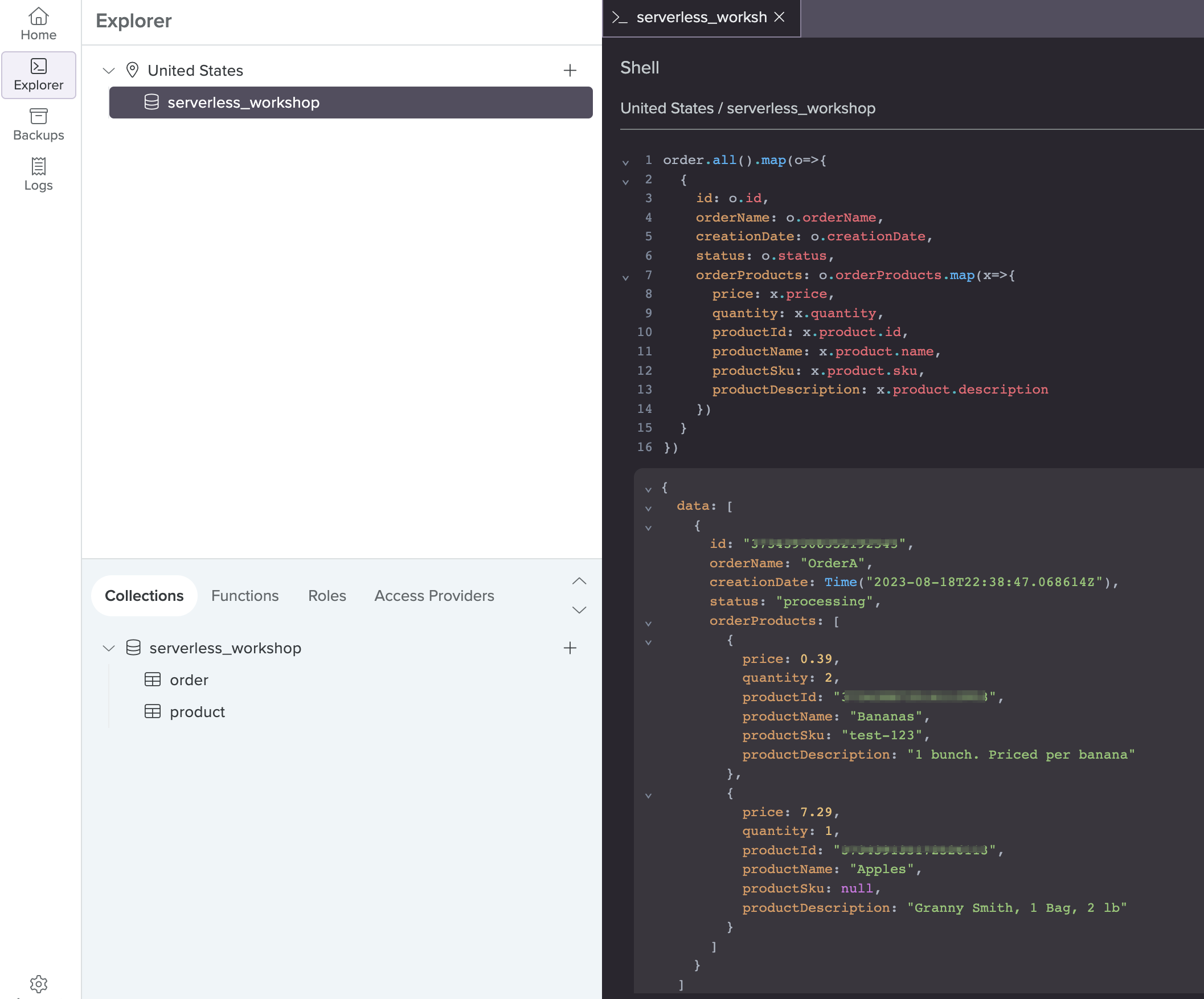
Notice that even though the order and product details are in separate documents, we’re able to combine them in a single query. Back at the Lambda function, the exact output you see above is returned from the Fauna client, encoded to a JSON object and returned to the caller.
Leveraging Fauna’s ability to make cross document joins allows us to save on bandwidth and latency. It also makes our code cleaner and easier to understand.
Lambda Layers
Inside the server sub-folder you will also notice we have a folder named layers. This folder contains a logger.py and a utils.py file, which were deployed as Lambda Layers. All of the other lambda functions share Lambda Layers in a centralized way. For example, at the top of the order_service.py file, on line 6, we import from logger.py, and on line 8, we import from utils.py:
4import json
5import utils
6import logger
7
8from utils import Fauna, load_config
9from fauna import fqlExamine the code for the Fauna class and the load_config function in utils.py:
The Fauna class is just a subclass of FaunaClient, imported from the Fauna Python driver. We instantiate it and use it to send queries to the database. During instantiation, we provide it a config that contains a Fauna API Key for accessing our database.
class Fauna(FaunaClient):
@classmethod
def from_config(cls, config):
return cls(
secret=config['FAUNA']['secret']
)
The config is stored in AWS Parameter Store. And read back using the load_config helper function.
def load_config():
configuration = configparser.ConfigParser()
config_dict = {}
try:
param_details = boto_client.get_parameters_by_path(
Path=FAUNA_CONFIG_PATH,
Recursive=False,
WithDecryption=True
)
if 'Parameters' in param_details and len(param_details.get('Parameters')) > 0:
for param in param_details.get('Parameters'):
config_dict.update(json.loads(param.get('Value')))
except:
logger.error("Encountered an error loading config from SSM.")
traceback.print_exc()
finally:
configuration['FAUNA'] = config_dict
return configurationRight now, values are stored as plain text in the parameter store. In Lab2, we’ll show you how to best secure them using encryption and AWS KMS.
Computing in context of data
We’ve previously seen the Fauna capabilities of making cross document joins, which improves the latency of our API. The benefits of the rich querying capability of the Fauna query language doesn’t stop there. The query below is for the POST /order (aka “create order”) API, and demonstrates another powerful feature of the query language: the abiliity to express business logic inside the query.
Let’s say the body of the request to the API is formatted as such:
{
"orderName": "Example",
"cart":
[
{
"price": "6.27",
"productId": "123456789101112131415",
"quantity": 1
},
]
}
where cart is a list of productId, price and quantity requested. Given that, let’s now look at how Fauna handles this payload:
59response = db.query(
60 fql("""
61 ${cart}.forEach(x=>{
62 let p = product.byId(x.productId)
63 let updatedQty = p.quantity - x.quantity
64
65 if (updatedQty < 0) {
66 abort("Insufficient stock for product " + p.name +
67 ": Requested quantity=" + x.quantity)
68 } else {
69 p.update({
70 quantity: updatedQty,
71 backordered: p.backorderedLimit > updatedQty
72 })
73 }
74 })
75
76 order.create({
77 orderName: ${orderName},
78 creationDate: Time.now(),
79 status: 'processing',
80 orderProducts: ${cart}.map(x=>{
81 product: product.byId(x.productId),
82 quantity: x.quantity,
83 price: x.price
84 })
85 }) {
86 id,
87 orderName,
88 creationDate,
89 status,
90 orderProducts
91 }
92 """,
93 cart=payload['orderProducts'],
94 orderName=payload['orderName']
95 )
96)- On line 61, we loop through the list of products.
- On line 62, given a productId, we retrieve the product information.
- On line 63, the payload tells us how much of the product is requested and we compare it to the product’s quantity on hand.
- On line 66, if the quantity requested is greater than the quantity in stock, we abort the transaction.
- Otherwise, we update the product’s quantity after subtracting the quantity requested, and finally we create the Order (line 76).
Being able to handle the business logic within the query provides 2 major benefits:
- Improved latency, as we don’t have to issue multiple requests to the database.
- Transactionality - The entire query and every mutation either succeeds, aborts or fails. If we implemented the above with multiple requests, any failed requests will result in our data being partially updated.
Onto the next lab
Now that you understand the baseline architecture, let’s continue by adding necessary elements needed inside our SaaS application.