Lab1
Introducing a basic serverless web application
This first lab is a basic e-commerce application that introduces the core components of a serverless web application. In this lab, you will get familiar with the general components that make up a serverless web application, get introduced to Fauna – a distributed, serverless, multi-model database delivered as an API – and see how it seamlessly fits in with the rest of the serverless components.
In subsequent labs, you will use this web application to add features that are needed to build our final SaaS application.
Below is the high level architecture:
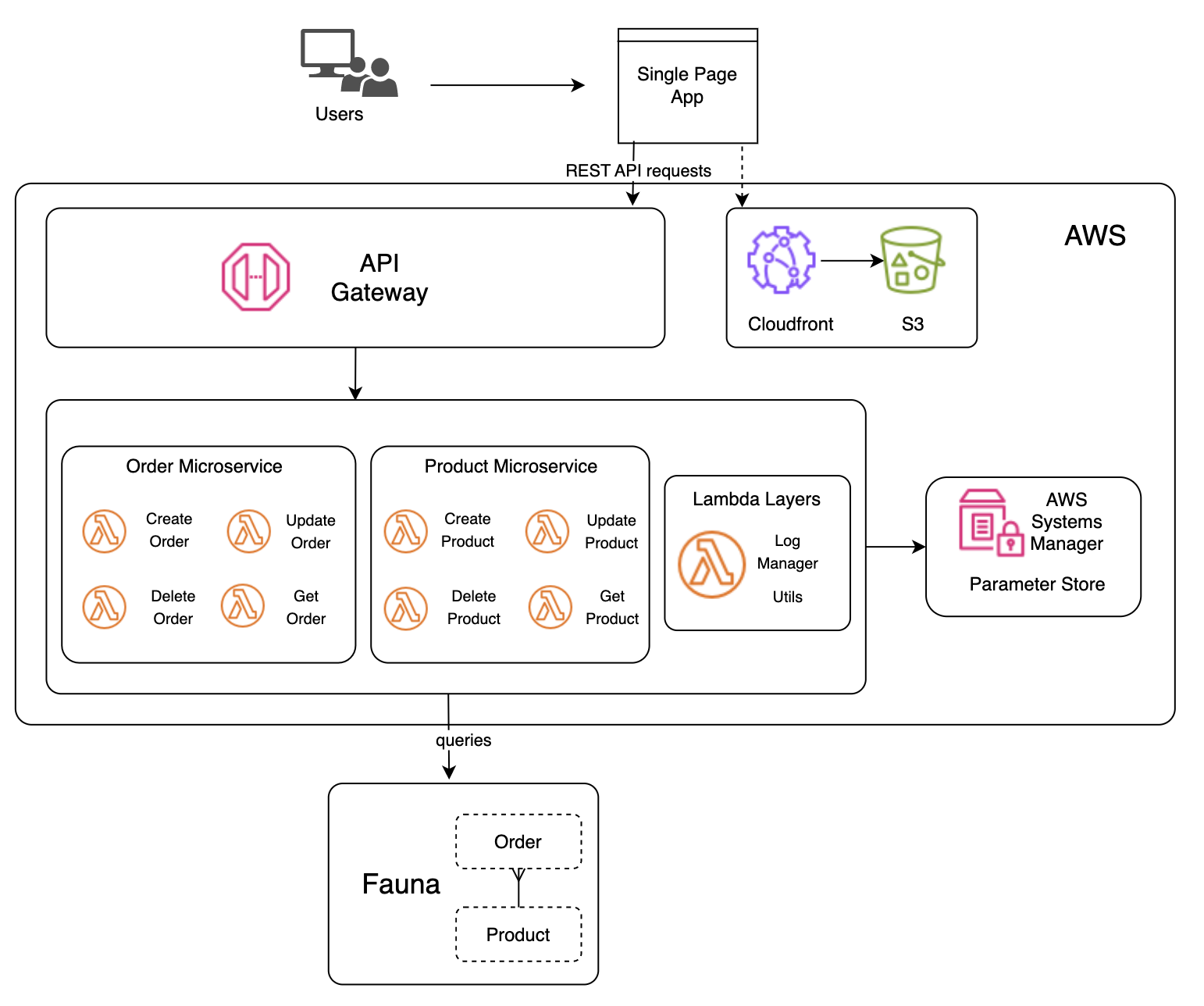
In looking at this architecture, you’ll see that we have a single page application at the top of the image. Our sample app is written in Vue, compiled with Vite and uploaded to an Amazon S3 bucket that’s cached by a CloudFront distribution.
The application accesses the microservices by making REST API calls through Amazon API Gateway, which routes the traffic to the appropriate function within each of our microservices. Here, we have 2 simple e-commerce microservices, Product and Order, that provide basic CRUD operations. The Lambdas interact with Fauna by issuing queries through a client, instantiated by a lightweight Python driver, and requires a Fauna API Key, which for now, is stored in AWS Systems Manager Parameter Store. Later on, we’ll show you how to better secure this API Key.
Serverless microservices
The notion of a microservice can be a bit different in a serverless environment. It’s true that each function could be a microservice. However, it’s more common to have a collection of functions that represent a logical microservice. In this case our microservice boundary is the API Gateway, backed by one or more Lambda functions. As shown in the architecture diagram, Order service has separate functions for create, get, update, and delete. These functions all operate on the same data and should be grouped together as a logical microservice.
Database Schema
Fauna can be consired “multi-model,” having the ability to support both relational and NoSQL/schemaless data models; Under the hood,
an object-relational query engine runs on top of data stored as documents. Our application contains 2 collections: Order and Product, where an Order is associated with multiple Products.
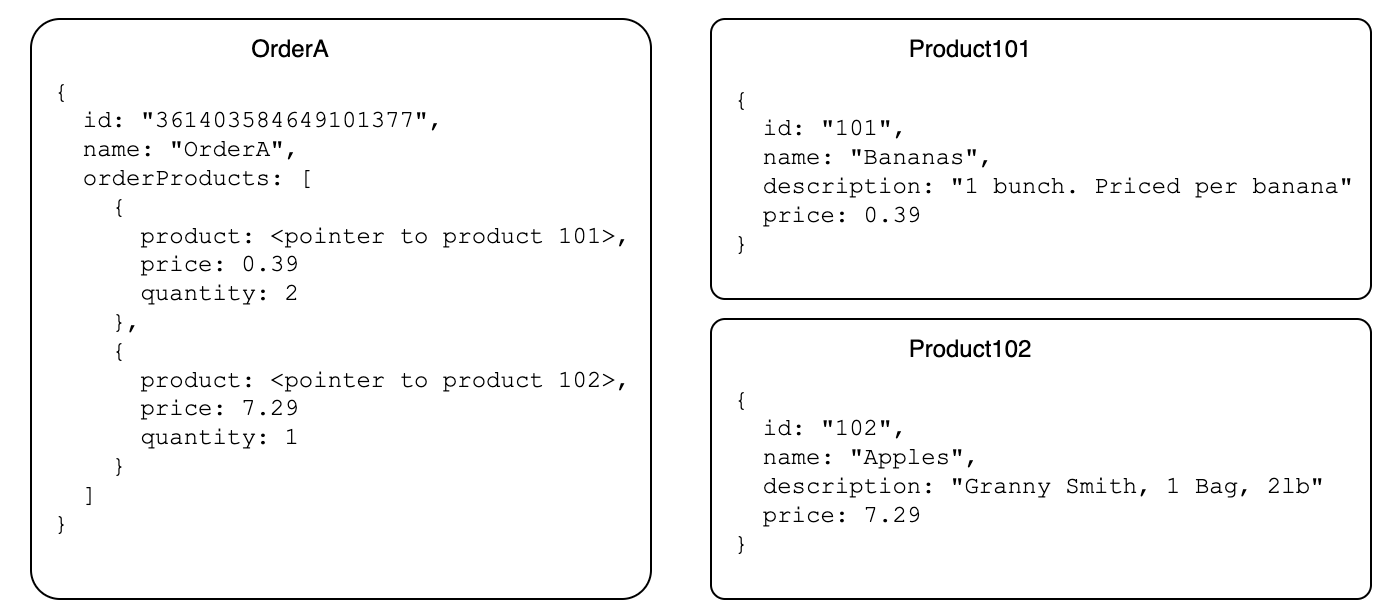
Later in the lab, you’ll see how data is stored as documents, including references to other documents, just like in the diagram above. Then we’ll show you some queries where documents are joined together, akin to performing joins in a relational database.
The examples and sample code provided in this workshop are intended to be consumed as instructional content. These will help you understand how various AWS services can be architected to build a solution while demonstrating best practices along the way. These examples are not intended for use in production environments.
Deploy the lab
Head over to the next section to deploy the sample app.